Adversarial Attacks against object detectors (2022)

For a detailed view of the code, check out the GitHub repository:
View the Code on GitHub
Go Back To Menu
Adversarial attacks against object
The proposed adversarial attack methods include hiding attack (HA), utilizing enhanced realistic constraints generation and feature interference reinforcement (FIR) for resilient object detection evasion. For Misclassification Attack (M.A.), the approach focuses on exploiting vulnerabilities in classifiers through adversarial perturbations, allowing the creation of inputs to manipulate model predictions and demonstrating techniques for both passing confidence tests and bypassing detection processes.
Abstract
The paper addresses the heightened vulnerability of object detection applications, particularly in real-world scenarios like autonomous driving and face recognition authentication, proposing systematic solutions for creating robust adversarial examples (AEs) against object detectors. It employs Interface Reinforcement and enhanced realistic constraints for Hiding attacks, while for Misclassification attacks, diverse adversarial samples and text-to-speech conversion are utilized to improve overall model stealthiness. The study evaluates AEs' effectiveness on popular object detection models like YOLO and RCNN, achieving a 90% success rate within a distance range of 1m to 20m and demonstrating transferability across different models with high success rates.
Introduction
The paper discusses YOLO (You Only Look Once) as a rapid object detection method using a single neural network for bounding box prediction and class labeling. Highlighting its broad applications in face detection, object tracking, and safety-critical tasks like autonomous driving, the study emphasizes the security challenges posed by adversarial examples (AEs) against object detectors in real-world scenarios. Recognizing the dynamic nature of object detection, the research aims to develop robust AEs specifically tailored for modern object detectors operating in diverse, real-world conditions, with a focus on long ranges, wide angles, and varying environmental circumstances.
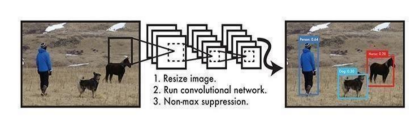
Design Of Yolo
The paper explores Hiding Attack (HA) and Misclassification Attack (MA) on object detectors, proposing techniques like Enhanced Realistic Constraints Generation and Feature-Interference Reinforcement (FIR) to enhance resiliency. For HA, FIR impacts both hidden layers and the final prediction layer early in categorization, addressing resistance to changes in physical circumstances. The study highlights the vulnerability of classifiers to misclassification attacks, emphasizing the need for robust techniques given constraints in picture transformations and the necessity for effectiveness at greater ranges and wider angles in practical scenarios.
Exisiting system
Although many algorithms and many attacks occurred in
recent years there is no particular knowledge or not many
research papers for adversarial attack examples.
• Object detection itself is the problem while detecting certain
objects from various angles, multiple illuminations, and so
on.
• It is really difficult for users to observe detected objects
while doing some work mainly driving.
• Robustness of existing systems is not enough
Disadvantages
• Robustness is still not sufficient.
• Text-to-speech conversion is not available.
• Short distances are only concentrated.
• Narrow angles and limited environments are considered.
• Accuracy is less.
Proposed System
The paper focuses on object detection, utilizing the YOLO framework and CNN algorithm for training. Object detection aims to identify and filter objects in images, particularly emphasizing applications in autonomous vehicles recognizing traffic signs over 15m distance and 20-degree angles. The system incorporates text-to-speech conversion in Python for user accessibility. The study explores adversarial examples, including Hiding Attacks (HA) and Misclassification Attacks (MA), proposing innovative methods to enhance attack resilience while emphasizing the benefits of text-to-speech conversion for users.
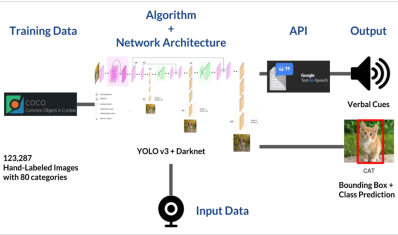
Proposed diagram
Adversarial attacks against ML
Hiding attack
Given the relative mobility of objects and detectors, the variety of surroundings, etc., developing robust AEs against object detectors in the actual world is not easy. Figure 1 shows a real-world illustration of an adversarial attack (HA of a person) against an autonomous object detector. The angles and distances between the person and the AE fluctuate as it approaches the AE. As a result, the perturbations in the AE detected by the object detector at various points, such as A, B, C, and D as illustrated in the figure, reveal various sizes, forms, and light reflections. This relative motion between the item and the detector necessitates the use of extremely robust AEs, despite their static nature. Since the white-box adversarial approach is the main topic of this research, we must access the target model (which includes its characteristics and structure). We also conducted some preliminary research on the black-box adversarial attack using the transferability of our AEs, assuming that we are unaware of any specifics on the target black-box models
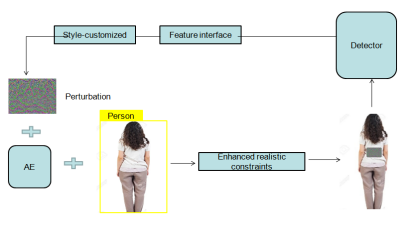
Hiding attack
Feature Interface Reinforcement
This research introduces a novel approach for generating robust adversarial examples (AEs) against object detectors. The proposed loss function not only falsifies prediction outcomes but also disrupts object features in hidden layers, enhancing the deception of prediction results. The feature-interference reinforcement (FIR) technique is highlighted for its effectiveness in boosting AEs' robustness, demonstrating a 7% improvement in both distance and angle parameters. The approach selectively targets a subset of hidden layers in the YOLO V3 architecture, effectively balancing complexity and optimization.
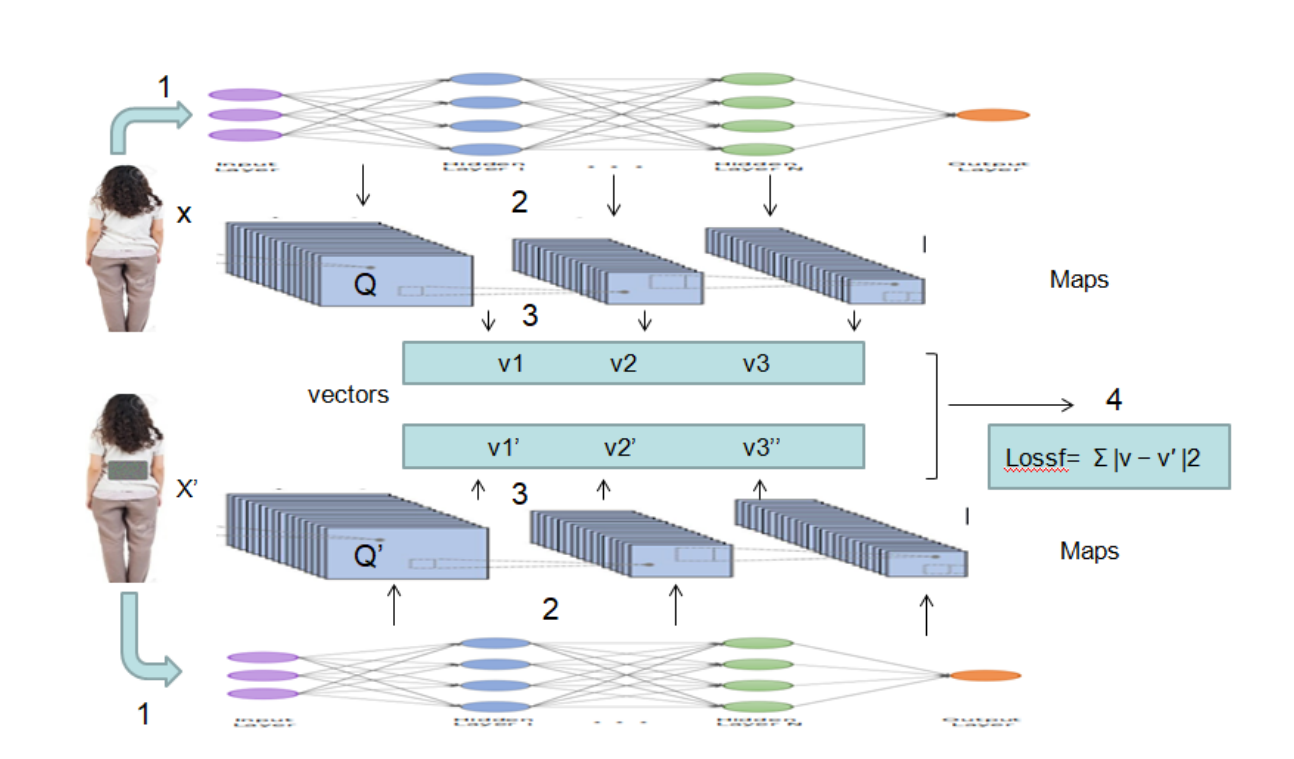
Misclassification attack
Object detectors may be tricked by the misleading Attention and Classification Attack (MACA), which can produce adversarial patches. In particular, we suggest a fresh method for creating adversarial patches to trick the object detector. Our method limits the adversarial patches’ noise and tries to produce adversarial patches that look aesthetically similar to real photos. To make adversarial patches more resilient, the approach replicates a complicated external physical environment and the 3D transformations of non-rigid objects. We test our technique against modern object detectors and show that it is highly adaptable to a variety of detectors. Numerous tests demonstrate that it is possible to retain the transferability of adversarial patches among various models when transferring the digital adversarial patches to the actual world [7] This is helpful to us as attackers in any situation when we must fulfil some confidence requirements in a class in a system in order to achieve a security result. Typical instances include: • Authentication systems (by increasing our confidence in a certain subject, we "pass" an auth check); • Malware filters (by modifying malware to avoid detection or purposely inducing a false-positive, we weaken confidence). • Filters for obscenity. We may be testing these, and we want to either intentionally set them off or get around them. • Physical domain attacks, such as masking people or groups from facial recognition software or making a stop sign read as a 45 mph speed limit sign
Attack Approach
To illustrate adversarial perturbation, we recreated a remarkably straightforward hill climbing algorithm. This algorithm operates in a black-box environment and can be used to highlight misclassification, increase confidence in a class, or produce a minimally perturbed example of one class that will be classified in a different, chosen class. The fact that such a straightforward approach works and can be applied in so many various ways is significant in and of itself; we do not claim that the technique is original to us; rather, we just chose the simplest and most obvious way to do this[15] . The algorithm is described in the following pseudocode. In this instance, we are changing an image that is classified as class "X" into an image with >= 99% confidence in class "Y" by selecting "confidence in class Y" as our target

To put it another way, we increase the image’s random noise until confidence rises. The disturbed image is then used as our new base image. When adding noise, we begin by including 5% of the pixels in the image, and if this is unsuccessful, we reduce the percentage. This produces rather noisy images but is quick enough for a live demonstration (taking about three minutes on a model trained on the "ImageNet" corpus).

Evaluation
We implemented Hiding Attack (HA) and Misclassification Attack (MA) for multiple objects, including stop signs, cars, monitors in HA, and stop symbols, persons, and traffic lights in AA. Due to the space limit, we cannot present evaluation results for all the objects in different physical conditions. To facilitate the comparison with existing works, we choose the Person as an instance in this section to exaggerate the evaluation results of both MA and AA in various physical conditions since the other two state-of-the-art physical attacks against sensors also estimated their approaches. We registered the attacks against other objects.
Potential Defenses
As far as we are aware, there is no universal protection mechanism against adversarial attacks on object detectors. The feasibility of such attacks in the actual world is still being researched. As a result, we research the countermeasures to adversarial attacks on image classifiers and consider if similar techniques could be used to protect object detectors. We can divide the defense mechanisms into three categories:
1. Altering the inputs to disrupt or even get rid of the antagonistic perturbations, for as by using JPEG compression, randomization, median-filter, image rescaling, etc. Additionally, Fangzhou et al. suggested training a guided denoiser to eliminate the AE disturbances. The likelihood that any of these pixel-based image processing, transformation, and denoising techniques Because our AEs are produced using a variety of transformations and random noise, such approaches might not be able to successfully disrupt the perturbations in our AEs.
2. A potential defense strategy is the guided denoiser, which has been trained using a large number of AEs (including our own) against object detectors. Building the corpus of AEs is a difficult task, nevertheless. Improving models such gradients obfuscation, defense distillation, and adversarial training. Such defense, however, is only effective against re-attacks and transferrable attacks. We can get around it by creating new AEs against the revised models or using transferability. •using GAN to defeat AEs. GAN can be used to train a classifier to determine whether or not an input is adversarial.[
Future Work
Future investigations in this field are expected to build on the findings of our research. There are several methods to make this information better. Vulnerabilities should be eliminated and robustness should be increased for many applications to function properly. There should be several test cases run and different actions executed. To get a quick overview of the various adversarial assaults made against object detectors, we will also examine multiple research articles and different attacks. Our future effort will concentrate on various environments rather than a small number of environments and illuminations. Additionally, we attempt to foresee objects and different vulnerabilities. in order to protect our automated systems.
Conclusion
In this paper, we proposed a reliable and usable adversarial attack against object detectors used in the real world. To increase the robustness of AEs in the physical world against numerous circumstances, such as varying distances, angles, backdrops, illumination, etc., we specifically proposed feature-interference reinforcement, algorithm , and layered AEs.
Acknowledgements
We appreciate the authors of the paper "Seeing is not believing: Towards more robust adversarial attacks againt real world object detectors". We also value the assistance Prof. Mert Pese provided us with suggestions and clarified all our doubts to make this project.
For a detailed view of the code, check out the GitHub repository:
View the Code on GitHub