Object detection using YOLO and python(2021)

For a detailed view of the code, check out the GitHub repository:
View the Code on GitHub
Go Back To Menu
OBJECT DETECTION IN REAL TIME AND VOICE OUTPUT USING YOLO AND PYTTSX3
The proposed adversarial attack methods include hiding attack (HA), utilizing enhanced realistic constraints generation and feature interference reinforcement (FIR) for resilient object detection evasion. For Misclassification Attack (M.A.), the approach focuses on exploiting vulnerabilities in classifiers through adversarial perturbations, allowing the creation of inputs to manipulate model predictions and demonstrating techniques for both passing confidence tests and bypassing detection processes.
Abstract
Many people suffer from temporary and permanent disabilities. There are many blind people around the globe. According to WHO it is noted that almost 390 lakh people are completely blind and 2850 lakh people are purblind that is they are visually impaired. For improving their daily life to travelfromone place to other place many supporting or guiding system is developed and being developed. So, the basic idea for our proposed system is to design an auto- assistance system for visually impaired person. The disable person will not be able to visualize the object so this Auto-assistance system may helpful for them. Many systems have been implemented to achieve assisting system for blind people. Some system is still under research. Model that were implemented were having numerous disadvantages in detecting the objects. We propose a new system it will assistance the visually impaired person and is was developed using CNN (Convolution Neural Network). In deep learning model the most popular algorithm for object detection is CNN. The accuracy of the object would also be more than 95% which depends on the clarity of the image taken by the camera. The object detected would also be given message for the blind people with the object name detected. This system is a prototype model for assisting blind people. In this system we would be detecting the obstruction in the path of visually impaired person using Web Camera & help them to avoid the collisions. Here we are using object detection
Introduction
The objects that are present at indoor environment like table, bed, chairs etc. should not be near them. The images of the objects can be downloaded or can be captured. Images are classified by giving them a class label and it is called as localization of object if around the image object there is a bounding box drawn. Combining these two processes and for the object of image assigning a class label for which a bounding box drawn is a process of detecting an object. All the three process together is for recognizing an object. The approach for detecting objects with more speed is YOLO-You Only Look Once. This method would take image as an input, draw the bounding box and name the class label as this particular approach has a neural network that is single and peer to peer trained. This method would offer less accuracy but operates with more speed. In this approach, the image that is taken as input will be split into matrix of cells for bounding box prediction. By using x, y coordinates along with the height and width and the confidence bounding box will be calculated for the matrix of cell. Based on matrix cell class is also predicted.
Motivation
Vision loss or completely blind people cannot detect the object or obstacles in their surroundings because of their vision problem. They always need some assisting or supporting system in their life. Solution has been found many years ago for this now gradually the techniques are improving due to evolution and integration in technology. In daily life blind people are using assisting systems that are developed while some are still in the research stage.
Exisisting system
In Existing System, the objects are detected and it is assisted to the completely blind people to make their daily life comfortable. In this system algorithms such as Convolutional Neural Network (CNN) and also Haar Cascade are compared with each other based on the object detection. Some of the entities like cup, person and ball were used in experiment for detecting and classifying. The algorithm used for the detection of face is Haar cascade which is a basic algorithm and for detection of objects CNN is the basic algorithm. This system was built only for detecting objects and the comparison was done between the algorithms which were not a favour for blind people. There is no any message for the blind people if any object or obstacles are identified.
Disadvantages
• Contains only 3 classes (person, ball, cup)
• So, if there are any other obstacles visually impaired person can’t identify.
• Text to speech is not available (identified object is not dictated to person)
• Narrow angles and limited environments are considered.
•Using Haar Cascade algorithm accuracy will be less.
Proposed System
we propose a new auto assisting system which will identify more than 3 classes from the video frames. So, the person can identify more obstacles in front of their way and avoid them. This makes the auto assisting system for visually impaired people more meaningful and helpful. After detecting the objects from the video frame this system will speak what object is detected. Here text-to-speech conversion is done so this system is really a boon for visually impaired people
Advantages
•Text to speech facility is available.
• Comfortable and safe.
• Text to speech is not available (identified object is not dictated to person)
• number of objects can be trained.
System Architecture
The design part includes the system architecture. It explains the workflow of the system
proposed. The architecture mainly explains the data is being modified. How it is being used and
how the results vary with it.
The scene for vision will be captured at different sampling rates. The images that are
captured and acquired would undergo processing and that output would trigger an audio
message for the person, the audio message will depend on the object detected. This is shown
briefly in below diagram
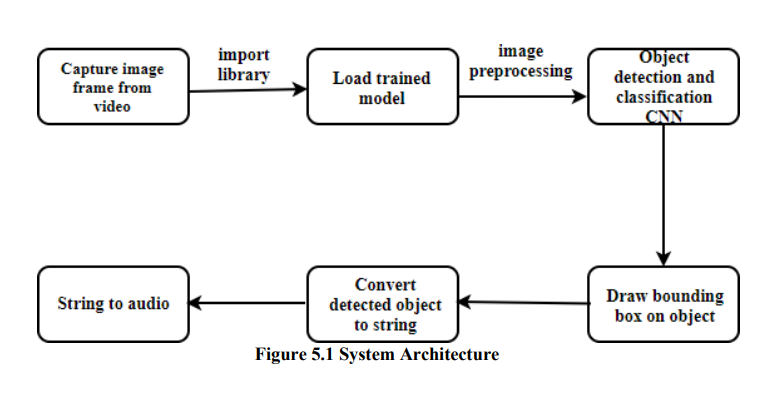
The images are captured as a frame from the video
. This is the first step and the
respective images may be shades of grey image or combination of color image.
.The model will be trained using the libraries that are imported to the system and this
particular model will be loaded to system.
.The images can be of different sizes so they are preprocessed, means the images size
are rearranged, rotation is done if required and shape is rearranged if required.
.All images must be maintained with similar size.
CNN algorithm is used for detecting objects and for classifying objects.
. The objects are converted to a string by drawing a boundary box for those objects that are
detected and classified.
. The string that was generated will be further converted in to an audio message using the
pytts.
.Later the result would be the audio of the object that was detected through speakers
Algorithm used
Depending on the data input the information is decrypted on different layers which
was encrypted by using layers of NN technique done by DL. Let us take an example of
recognizing an image app in which the features like edges that are sharp or less contrast is
identified by one of the layers, other layers can be used in identifying separate shapes.
After the first two layers then 3
rd layer can be used to decrypt to see what is in image.
By learning from the previous layers by differentiating objects these layers can be achieved.
The architecture based on DL that has been using nowadays are mainly depended on ANN
which would use many layers of non-sequential processing for extracting feature and
alteration.
Dataset
The first step in designing a network in deep learning is to collect the dataset initially.
The images with the label associated with the images are required for designing the system.
Categories that are with finite number sets produce the labels for the images (ex: cat, wood,
flowers etc).
Furthermore, the images selected for each category should be having balanced number
of images (i.e dog 1000 images then cat also 1000 images). If the images selected are not equal
means, if the flower images are selected as two times greater than the cat image then the image
of table is selected thrice more than flower image this would make the system unbiased. This is
a common problem in machine learning when we are designing the system to make it work as a
human brain. The class that is not balanced problem can be overcome using many techniques
but the easy way to overwhelmed and is used as a balanced data or class while designing the
network
Test Cases
A collection of statements that has the procedure and details about the functionalities underwent for testing is called test case. By writing or developing test case it would help in finding out the faults that the system has and no need of remembering the errors as everything would be noted in the test case. To make sure that the system is ready for release and can be used by customers for every functional requirements atleast there must be around 2 to 3 test cases based on valid and invalid input. The requirement containing sub fields must also be tested with positive and negative values to make sure that the system is suitable for real time
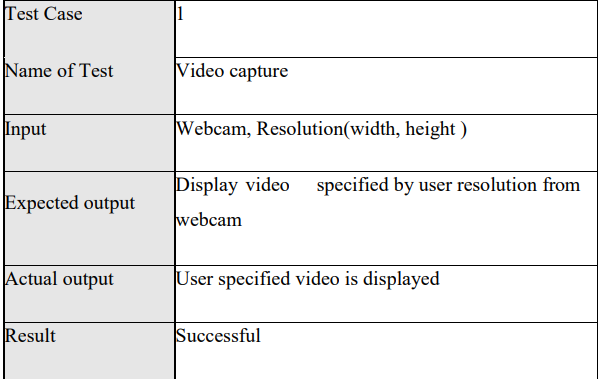
Video capture:
The images are captured from the webcam and the video has to be displayed from the webcam as specified by the user. The input would be video from the webcam with good resolution. Output expected isto display video fromwebcam, resolution as specified by the user. This test case has executed and successfully passed as per the expected output as shown in below table
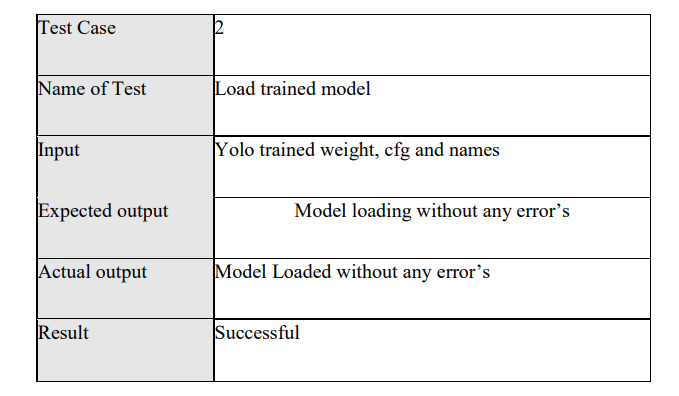
Loading trained model:
The models that are trained are loaded to check if any error exists in the model. The input would be video yolo trained weight, cfg and the names ofthe model. Output expected is to model getting loaded without displaying any error. This test case has been executed and successfully passed as per the expected output as shown in below table
Classify objects:
: The images are captured from the webcam are resized or preprocessed for classifying the objects from the image. The input would be image that is resized from the webcam. Output expected is to classify the objects from the input image specified by the user. Thistest case has been executed and successfully passed as per the expected output as shown in below table
Localize object location:
: The images are captured from the webcam and the image that are resized or preprocessed will be used to localize the objects from the image input that was classified. The input would be image resized from the webcam. Output expected is to localize objects from the input image that is classified. Thistest case has been executed and successfully passed as per the expected output as shown in below table

Display detected objects:
: The images are captured from the webcam and the object that is detected has to get plotted with the bounding box. The input would be image from the webcam with good resolution. Output expected is to display plot the bounding box around the object detected. This test case has been executed and successfully passed as per the expected output as shown in below table
Audio message:
The images are captured from the webcam would be localized and that particular image with the detected objects has marked with the bounding box and generates the output with the audio message as name of the object detected. The input would be localized and bounded image with detected object. Output expected is in the form of the audio message. The audio would be produced with the name of the detected object as a result. This test case has been executed and successfully passed as per the expected output as shown in below table
RESULT AND DISCUSSION
Result represents that program for recognition of object is implemented successfully using CNN (Convolutional Neural Netwrok). The aim is to help purblind people in making their life better by detecting and assisting them with the obstacle or object detected. Proposed model tells us that this program can be used for distinguishing between artifacts and supporting impaired people
Conclusion
A system based assisting network has been proposed in order to assist the purblind people and
completely blind people. The template that are matching the procedures conducted by experimenting
using OpenCV has formed a successful method that is multiscale and useful for the applications used
inside the surroundings. The constraints that are based on time and the range of detection are the
optimum numbers which need to be founded depending on the values of the factors based on the scaling
and the length and width of the image.
The objects detected are finally output as an acoustic message with the name of the object detected. The
accuracy will be depended upon the clarity of the image captured by the user. If the image looks similar
to other objects there may exist an ambiguity which would reduce the accuracy of the object detected.
Model is trained to detect 78 objects with a maximum of accuracy. The distance of the image getting
captured depends on the camera. The vision of the system for the accuracy it can be made better by
improving the constraints that are adapted for illuminating and changing for real life surroundings
Acknowledgements
I owe my deepest gratitude to Almighty for Everything
I sincerely owe my gratitude to all the persons who helped and guided me
in completing this Project work.
I would like to thank Dr. B S.M. Naidu, Chairman SITAR, a well known
academician for his modest and helping for all our academic Endeavors.
I are indebted to Dr. Sampoorna Naidu, Director, SITAR, for her moral
support and for providing me all the facilities during my College days
We would like to Thank Governing Council Members of our Organization.
I am thankful to Dr. H.V Byregowda Principal SITAR, Channapatna
without his help this Project would be dream.
We are thankful to Ms.Shalet Benvin Professor & Head of Department
of Computer Science and Engineering for his suggestions & Support.
I would like to sincerely thank my Project guide Ms.Shalet Benvin, Professor
& Head of the Department of Computer Science and Engineering for her invaluable
guidance, constant assistance and constructive suggestions for the effectiveness of
Project, without which this Project would not have been possible.
I would also like to thank all Department staff members who have always
been with me extending their precious suggestions, guidance and encouragement
throughout the Project.
Lastly, I would like to thank our parents and friends for their support,
encouragement and guidance throughout the Project.
For a detailed view of the code, check out the GitHub repository:
View the Code on GitHub